
TL;DR
HappyHorse-1.0 is currently #1 on Artificial Analysis for text-to-video (no audio) and image-to-video (no audio). Those rankings come from blind user votes + Elo, not self-reported benchmarks. The model still isn’t practically usable: no public API, no downloadable weights, and “coming soon” repo links (as of Apr 8, 2026). Some technical details are claimed (40-layer Transformer, multilingual audio-video), but none are independently verified. If you’re shipping a product, the “real” shortlist starts at models you can actually access - or you use an ad-focused tool like EzUGC to generate UGC-style ads fast without model-chasing.
I watch model leaderboards the way some people watch the stock market.
Most weeks it’s the usual suspects trading places by a few points. Then a totally unknown name shows up at #1 - and the links are basically “trust me bro, coming soon.”
That’s HappyHorse-1.0.
This is a clean breakdown of what’s confirmed, what’s only claimed, and what that gap means if you’re trying to build something real (not just win a Twitter thread).
A model can be “best” in blind voting and still be unusable for any serious product team.
How HappyHorse-1.0 appeared on the radar
Artificial Analysis Video Arena: what it is and why it matters
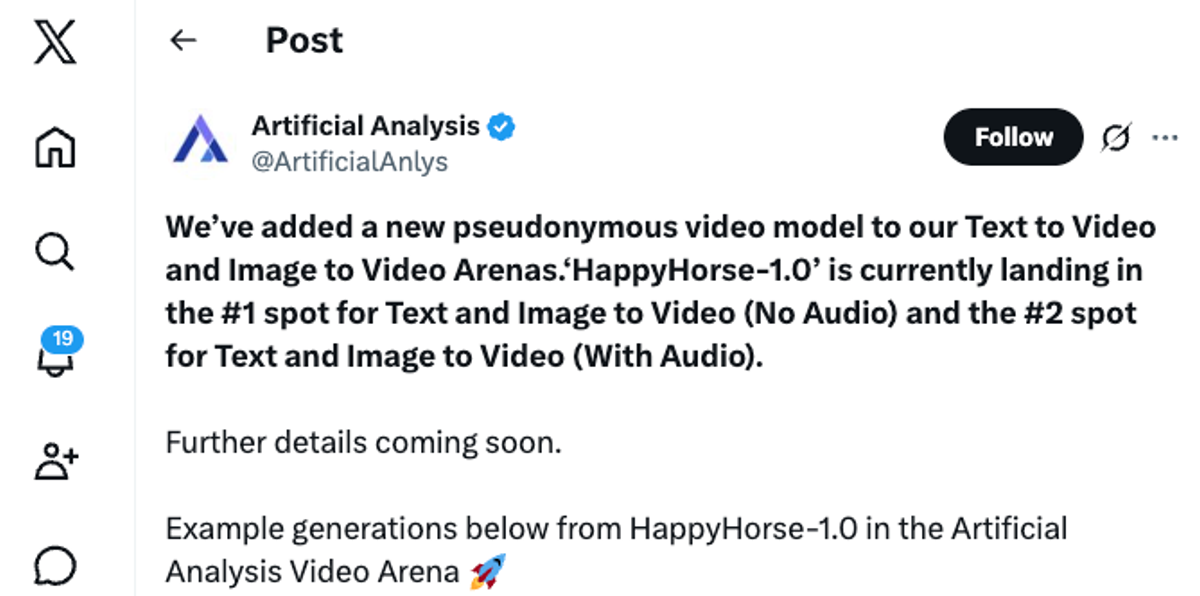
Artificial Analysis runs a video arena where users submit a text prompt or a reference image.
Two models generate outputs. Users see the two results side-by-side, don’t know which model made which, and vote for the one they prefer.
Blind user votes + Elo: not self-reported benchmarks
Most “rankings” in AI are builders reporting numbers about their own model.
This removes that incentive. The quality signal comes from aggregate preferences under blind conditions.
Elo differences are relative. The source analysis states:
- A 60-point Elo gap means one model wins roughly 58-59% of head-to-head matchups
- A 5-point gap is basically noise
T2V #1 (Elo 1333), I2V #1 (Elo 1392): the April 2026 snapshot
As of early April 2026, HappyHorse-1.0 sat at the top of multiple categories.
The numbers below are the key snapshot (publication date: April 8, 2026):
| Category | Elo | Rank |
|---|---|---|
| Text-to-Video (no audio) | 1333 | #1 |
| Image-to-Video (no audio) | 1392 | #1 |
| Text-to-Video (with audio) | 1205 | #2 |
| Image-to-Video (with audio) | 1161 | #2 |
The previous #1 in T2V without audio was Dreamina Seedance 2.0 at 1,273. That’s a 60-point gap.
In I2V no-audio, HappyHorse leads Seedance 2.0 by 37 points.
With audio included, Seedance edges ahead: the gap is 14 points in T2V with audio, and 1 point in I2V with audio.
One important honesty check: Elo for newly added models can swing hard. The source notes Seedance 2.0 has over 7,500 vote samples in the T2V category, and HappyHorse’s sample count isn’t publicly broken out yet. This conclusion has an expiration date.
What we know about the model (and what is just “from their website”)
Everything in this section is claimed by the model’s own site(s) and not independently verified as of April 8, 2026.
That doesn’t mean it’s false.
It means you shouldn’t architect your product around it yet.
Single self-attention Transformer, 40-layer design (claimed)
The description: a single unified Transformer with 40 layers.
Text tokens, a reference image latent, and noisy video and audio tokens are jointly denoised in one token sequence. The first and last 4 layers reportedly use modality-specific projections, while the middle 32 layers share parameters across modalities. No cross-attention.
A separate marketing site claims 15 billion parameters, but that number doesn’t appear on the primary domain and isn’t independently reported.
This is specific enough to be falsifiable. If weights drop, the internet will verify (or dunk on) these claims within hours.
Multilingual audio-video generation (claimed)
The site lists six languages for joint audio-video generation:
- Chinese
- English
- Japanese
- Korean
- German
- French
A separate page adds Cantonese as a seventh and mentions “ultra-low WER lip-sync.”
No public demo, weights, or API means you cannot properly test this. The arena outputs don’t systematically validate multilingual audio.
Text-to-video and image-to-video in one pipeline (reported)
The unified T2V + I2V story is at least consistent with how the model appears in the arena: the same model name ranks in both.
The site also claims joint audio synthesis (dialogue, ambient sounds, Foley) generated alongside video in one pass. The #2 ranks in the “with audio” categories suggest something is there.
But again: competitive in a leaderboard is not the same thing as shippable.
What’s still unverified (the stuff that makes builders nervous)
Team identity: pseudonymous
Nobody has publicly claimed credit. Artificial Analysis used the word “pseudonymous” when announcing the model’s addition.
People on X speculate it’s an Asia-based team (language list, timing patterns, prior stealth drops). That’s a vibe, not evidence.
“Open source” claims vs “coming soon” reality
The site states: “Base model, distilled model, super-resolution model, and inference code - all released.”
But as of April 8, 2026, the GitHub and Model Hub links are marked “coming soon” and aren’t accessible.
So you have a mismatch:
- The text says it’s released
- The links say it’s not
If you’ve ever shipped anything, you know which one counts.
Parameter count and hardware requirements: not independently confirmed
The 15B parameter claim appears on a secondary site.
The primary site mentions inference speeds - roughly 2 seconds for a 5-second clip at 256p, and roughly 38 seconds for 1080p on an H100 - but those are self-reported.
Without weights, nobody outside the creators can verify architecture, memory needs, or throughput.
WAN 2.7 speculation: plausible pattern, zero proof
Some speculate HappyHorse-1.0 is actually WAN 2.7 (a rumored next version of Alibaba’s WAN video family) running under a pseudonym.
The logic:
- WAN 2.6 sits on the leaderboard at Elo 1,189 for T2V (well below HappyHorse)
- Stealth drops before official launches have happened before
The precedent cited: in February 2026, a “mystery model” appeared, triggered a guessing game, and later turned out to be Z.ai’s GLM-5 doing a stealth stress test.
But patterns don’t prove identity. No weights, no API fingerprinting, no insider confirmation - nothing connects HappyHorse to WAN.
“I don’t know” is the correct answer here.
Why the “mystery origin” matters (even if you just care about output quality)
Elo is blind - the quality signal is still real
If HappyHorse consistently wins blind comparisons, that’s a real signal.
The voters don’t know the model name. They aren’t trying to help a brand. They’re just picking the better-looking clip.
So yes: the rank is meaningful.
Access uncertainty: quality and usability are different sports
Here’s the part that wrecks roadmaps.
As of today (Apr 8, 2026):
- No public API
- No downloadable weights
- No documented pricing
- No SLA
So for anyone building a pipeline, HappyHorse-1.0 effectively doesn’t exist yet.
What to watch if you want this to become “real”
Three signals move HappyHorse from “cool leaderboard entry” to “option I can ship”:
- A GitHub repo with actual weights and inference code
- A Hugging Face model card with verifiable details + license
- An API endpoint with documented pricing
As of publication: none exist.
The marketer’s version of this lesson
If your goal is paid social output, you don’t win by chasing the #1 research model.
You win by running more iterations: more hooks, more angles, more creator styles, faster revision loops.
That’s why products like EzUGC exist. Traditional UGC is about $200/video when you’re hiring creators. EzUGC generates AI UGC-style ads for about $5/video, in minutes, with consistent structure and fewer “creator brief -> wait -> reshoot” headaches.
If you want to test 20 variants before Friday, you care less about leaderboard glory and more about throughput.
Where it sits in the current video model landscape
Current T2V leaderboard context (early April 2026)
Here’s the top of the Artificial Analysis T2V leaderboard (no audio), early April 2026. Note the operational punchline: the top two are not publicly accessible.
| Rank | Model | Elo | API Available | Released |
|---|---|---|---|---|
| #1 | HappyHorse-1.0 | 1333 | No | Apr 2026 |
| #2 | Seedance 2.0 720p | 1273 | No public API | Mar 2026 |
| #3 | SkyReels V4 | 1245 | Yes ($7.20/min) | Mar 2026 |
| #4 | Kling 3.0 1080p Pro | 1241 | Yes ($13.44/min) | Feb 2026 |
| #5 | PixVerse V6 | 1240 | Yes ($5.40/min) | Mar 2026 |
I2V (no audio) follows the same pattern in the source: HappyHorse at 1,392, Seedance 2.0 at 1,355, PixVerse V6 at 1,338, Grok Imagine Video at 1,333, Kling 3.0 Omni at 1,297.
Positions 3 through 5 in T2V are separated by 5 Elo points - basically a statistical tie.

What this means for teams evaluating video generation stacks
Two separate questions:
- Which model wins blind comparisons right now? HappyHorse-1.0 (based on current Elo).
- Which model can you integrate today? Not HappyHorse.
So the “practical leaderboard” starts at #3.
The source’s takeaway: SkyReels V4 has the best quality-to-price ratio among accessible options. Kling 3.0 Pro costs more but runs 1080p natively. PixVerse V6 is the cheapest per minute in the top tier.
If HappyHorse drops weights or an API soon, the calculus changes fast.
It’s also possible nothing materializes for months.
FAQ
Who made HappyHorse-1.0?
Unknown. Artificial Analysis describes it as “pseudonymous.” Community speculation points to an Asia-based team, but no organization has claimed it.
Is HappyHorse-1.0 available to use right now?
Not in any production-ready way. GitHub and Model Hub links say “coming soon.” No public API, no downloadable weights, no documented pricing as of April 8, 2026.
Is HappyHorse-1.0 the same as WAN 2.7?
Unconfirmed. The speculation exists because anonymous pre-launch drops are common and there are recent precedents, but no direct evidence connects HappyHorse to Alibaba’s WAN family.
How does Artificial Analysis rank video models?
Blind user voting. Users compare two videos from the same prompt without knowing which model made which, then pick their preference. Votes feed into an Elo rating system.
When will HappyHorse-1.0 weights be released?
No timeline given. “Coming soon” for both GitHub and Model Hub. No public commitment to hold anyone to.
The leaderboard numbers are real.
Everything else - team, weights, access, timeline - is pending.
If what you actually need is ad output (not model archaeology), you can skip the waiting and generate UGC-style ads in minutes with EzUGC: https://app.ezugc.ai
Sources and citations
- Artificial Analysis Video leaderboard (arena + ranking methodology) · Artificial Analysis
Reference for the Video Arena concept, rankings, and the idea of blind preference voting.
- Elo rating system overview · Wikipedia
Background on Elo scoring and how to interpret rating gaps in head-to-head settings.
- Hugging Face model sharing basics (model cards, releases, licensing) · Hugging Face
Useful context for what a real release looks like (model card, license, reproducibility).
Frequently asked questions
Direct answers pulled into the page to improve answer-first relevance and scanability.